
Partir du métier, pas de la technique
Quand j’ai attaqué la modélisation de SmartPlanning, j’aurais pu ouvrir directement un fichier schema.prisma et commencer à écrire des tables. Mais une base de données mal pensée, c’est une dette technique qu’on traîne pendant des mois. J’ai donc posé les bonnes questions en amont : qui utilise l’application ? Quelles données sont manipulées par chaque rôle ? Et surtout, comment garantir l’isolation entre les entreprises clientes ?
J’ai suivi la méthode Merise : MCD (modèle conceptuel, indépendant de toute technologie) puis MLD (modèle logique, tables relationnelles), avant d’arriver au schéma physique PostgreSQL implémenté via Prisma. Le MCD a été réalisé avec Looping, un outil dédié qui permet de poser les entités et associations sans se soucir de la technique à ce stade.
Cette démarche a un avantage concret : quand on modifie une règle métier, on sait exactement quelles tables sont impactées.
Pourquoi PostgreSQL
J’ai évalué trois options : MongoDB, MySQL et PostgreSQL. Le choix s’est imposé rapidement.
MongoDB propose un modèle schema-less et une cohérence “éventuelle” par défaut. Pour un SaaS de planning avec des congés, des paiements Stripe et des workflows d’approbation, j’avais besoin de garanties ACID complètes, pas d’une cohérence approximative.
MySQL aurait pu convenir, mais PostgreSQL offre des avantages décisifs pour du multi-tenant : le type JSONB natif, le Row Level Security (RLS), les index avancés (B-Tree, GIN, partiels, composites) et un typage strict extensible. L’écosystème Next.js est aussi excellent via Prisma, avec un support complet des transactions imbriquées.
Pourquoi Prisma ORM
Face à TypeORM et Drizzle, Prisma l’a emporté sur trois critères : la type-safety générée automatiquement depuis le schéma, les migrations automatiques (avec possibilité de SQL brut), et une courbe d’apprentissage accessible. Le support natif de Next.js a aussi pesé dans la balance.
Un point technique important : en développement, Next.js recharge les modules à chaque modification. Sans précaution, chaque rechargement crée une nouvelle connexion à la base. J’ai donc initialisé le client Prisma en singleton :
import { PrismaClient } from "@prisma/client";
const globalForPrisma = globalThis as unknown as {
prisma: PrismaClient | undefined;
};
export const prisma = globalForPrisma.prisma ?? new PrismaClient();
if (process.env.NODE_ENV !== "production") {
globalForPrisma.prisma = prisma;
}En complément de Prisma Studio (interface web CRUD), j’utilise DBeaver pour les requêtes SQL manuelles et la visualisation des diagrammes ER.
Architecture multi-tenant : l’analogie de l’immeuble
SmartPlanning, c’est un immeuble. Chaque entreprise cliente est un appartement. Tous partagent le même bâtiment (la base de données), mais chacun a sa propre clé : le companyId.
J’ai évalué trois stratégies d’isolation :
- Base séparée par client : isolation maximale, mais coût d’infrastructure élevé et migrations à appliquer N fois.
- Schéma séparé par client : bon compromis, mais les migrations deviennent complexes à orchestrer.
- Colonne partagée
companyId: simple, économique, avec un risque maîtrisable si chaque requête filtre systématiquement.
J’ai choisi la colonne partagée, pragmatique pour la cible de SmartPlanning : des TPE/PME avec moins de 500 utilisateurs par entreprise. Chaque table métier porte un companyId comme discriminant :
model Employee {
id String @id @default(cuid())
firstName String
lastName String
email String @unique
role UserRole @default(EMPLOYEE)
isActive Boolean @default(true)
companyId String
company Company @relation(fields: [companyId], references: [id], onDelete: Cascade)
teamId String?
team Team? @relation(fields: [teamId], references: [id], onDelete: SetNull)
@@index([companyId])
@@index([companyId, isActive])
@@map("employees")
}Toutes les requêtes Prisma filtrent par companyId. Des tests unitaires vérifient systématiquement la présence de ce filtre. Une exception : le modèle PersonalTask n’a pas de companyId car il est 100 % privé, filtré uniquement par userId.
Le modèle de données complet
Le schéma comprend 20 tables principales et 4 tables NextAuth. Le MCD ci-dessous, réalisé avec Looping selon la méthode Merise, représente l’ensemble des entités et leurs associations avant toute traduction en tables relationnelles :
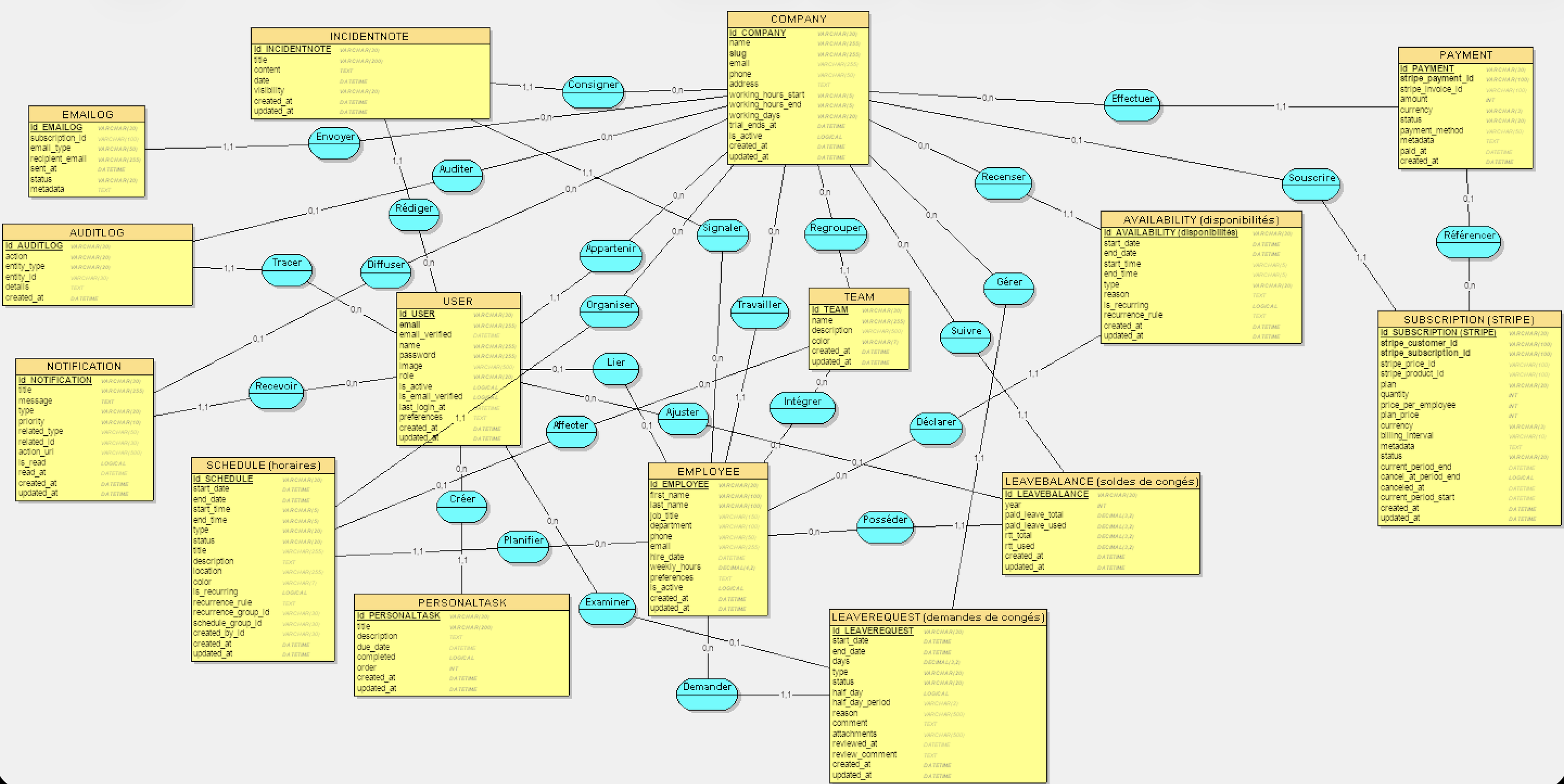 MCD SmartPlanning : 20 entités, leurs attributs et associations — réalisé avec Looping
MCD SmartPlanning : 20 entités, leurs attributs et associations — réalisé avec Looping
Voici les entités clés :
- Company : racine du multi-tenant, 11 associations. Supprimer une entreprise supprime tout en cascade (droit à l’oubli RGPD).
- User : authentification et 4 rôles RBAC (
SYSTEM_ADMIN > DIRECTOR > MANAGER > EMPLOYEE). - Employee : profil métier RH, séparé de User. Un
SYSTEM_ADMINn’a pas d’Employee associé. - Team, Schedule : 8 types de créneaux (
WORK,MEETING,BREAK,TRAINING,REMOTE,ON_CALL,OVERTIME,REST). - LeaveRequest / LeaveBalance : workflow d’approbation
PENDINGpuisAPPROVEDouREJECTED. - IncidentNote : visibilité RBAC à 3 niveaux. AuditLog : traçabilité complète.
- Subscription / Payment : intégration Stripe per-seat (2,90 EUR/employé).
- Conversation / Message : messagerie interne entre membres.
Le tout repose sur 16 enums PostgreSQL pour un typage strict à trois niveaux : TypeScript compile-time, Zod runtime, et PostgreSQL au niveau base.
Décisions d’implémentation Prisma
Identifiants CUID
Chaque entité utilise des CUID (@default(cuid())) plutôt que des IDs auto-incrémentés. Un ID séquentiel (1, 2, 3…) permet de deviner les ressources voisines. Un CUID comme clxyz1234abcd est non-devinable, ce qui renforce la sécurité de l’API.
Soft delete plutôt que suppression physique
Quand un employé quitte l’entreprise, je passe isActive à false au lieu de supprimer la ligne. Cela préserve l’historique de facturation Stripe et les statistiques de congés. Cette décision a littéralement sauvé la cohérence de la facturation en production.
Relations et cascades
// CASCADE : suppression entreprise = suppression totale
company Company @relation(fields: [companyId], references: [id], onDelete: Cascade)
// SetNull : le paiement survit à la suppression de l'abonnement
subscription Subscription? @relation(fields: [subscriptionId], references: [id], onDelete: SetNull)Les relations optionnelles couvrent les cas réels : un employé peut ne pas avoir d’équipe, un utilisateur peut ne pas être rattaché à une entreprise (cas du SYSTEM_ADMIN).
Indexation ciblée
Chaque table métier a un index sur companyId. J’ai ajouté des index composites pour les requêtes fréquentes : (companyId, status) pour filtrer les demandes de congé en attente, (employeeId, year) pour les soldes annuels, et un index UNIQUE sur email.
Convention de nommage
Le @@map permet de garder le camelCase dans le code TypeScript tout en respectant la convention snake_case côté PostgreSQL :
model LeaveRequest {
// ...
@@map("leave_requests")
}Les 22 migrations sont versionnées dans Git, ce qui garantit la reproductibilité du schéma sur chaque environnement.
Bilan critique
Ce qui fonctionne bien
Le multi-tenant par companyId est solide et simple à raisonner. Le typage Prisma couplé à Zod élimine une classe entière de bugs : si un enum change dans le schéma, TypeScript refuse de compiler. Le soft delete a prouvé sa valeur dès les premiers tests de facturation Stripe.
Les difficultés rencontrées
La synchronisation Stripe/PostgreSQL pour le modèle per-seat a été le point le plus délicat. Quand un employé est ajouté, il faut mettre à jour l’abonnement Stripe et la base en même temps, avec gestion des cas d’erreur. Autre problème : Prisma est incompatible avec l’Edge Runtime de Next.js. Impossible d’appeler Prisma dans un middleware Edge. La solution a été d’enrichir le JWT avec les données nécessaires pour éviter les appels base dans le middleware.
Ce que je ferais différemment
J’intégrerais PgBouncer dès le départ pour le pooling de connexions, plutôt que de l’ajouter après coup. Et je mettrais en place des ADR (Architecture Decision Records) pour documenter chaque choix technique au moment où il est pris, au lieu de reconstituer la logique a posteriori.
La base de données est le socle de tout le projet. Prendre le temps de la modéliser correctement m’a fait gagner des semaines sur le développement des fonctionnalités.