
Pourquoi un VPS autogéré plutôt qu’un PaaS
Quand on lance un SaaS, la tentation est forte de déployer sur Vercel, AWS ou Heroku et de ne plus y penser. J’ai fait le choix inverse pour SmartPlanning : un VPS OVH autogéré sous Ubuntu 24.04 LTS (4 vCPU, 8 Go RAM). Ce n’est pas une question de budget : c’est un choix de maîtrise.
En tant que Concepteur Développeur d’Applications, je voulais comprendre chaque maillon de la chaîne : la configuration de l’OS, le durcissement SSH, le pare-feu, le reverse proxy, le renouvellement SSL, l’orchestration des conteneurs. Un PaaS abstrait tout cela. C’est confortable, mais ça ne forme pas. Sur un VPS, chaque problème est une occasion d’apprendre : et chaque solution est documentée dans mon guide de déploiement sur Confluence.
Cette approche m’a confronté à des problématiques concrètes d’administration système que je n’aurais jamais rencontrées autrement. Et quand un incident de sécurité a frappé en décembre 2025, c’est cette connaissance en profondeur qui m’a permis de réagir rapidement.
Conteneurisation Docker : quatre services, une orchestration
SmartPlanning tourne dans quatre conteneurs Docker orchestrés par Docker Compose :
- app : l’application Next.js compilée en mode standalone (taille d’image minimisée, démarrage rapide)
- postgres : PostgreSQL 16 Alpine, données persistées dans un volume Docker dédié
- redis : Redis 7 Alpine pour le cache et la gestion des sessions
- umami : analytics auto-hébergé, conforme RGPD, sans cookies tiers
Durcissement des conteneurs
Les conteneurs ne tournent pas avec les réglages par défaut. Chaque service est durci selon les bonnes pratiques OWASP Docker :
- Utilisateur non-root : aucun conteneur ne s’exécute en tant que root
- Système de fichiers en lecture seule : le conteneur ne peut pas modifier son propre filesystem
- Suppression de toutes les capacités Linux (
cap_drop: ALL) : le conteneur n’a aucun privilège système superflu - Interdiction d’élévation de privilèges (
no-new-privileges) : même si un attaquant prend le contrôle d’un processus, il ne peut pas escalader ses droits
Le réseau Docker interne isole la communication inter-services. Redis, par exemple, n’est jamais exposé sur internet : seul le conteneur app peut y accéder via le réseau interne.
Reverse proxy Nginx et SSL
Devant l’application, Nginx joue un triple rôle :
- Routage : les requêtes vers
smartplanning.frsont dirigées vers le conteneur app, celles versanalytics.smartplanning.frvers Umami - Chiffrement HTTPS : certificat SSL Let’s Encrypt avec renouvellement automatique tous les 90 jours via Certbot
- Optimisations de performance : compression gzip, cache des fichiers statiques, HTTP/2
Cette couche Nginx est le seul point d’entrée réseau. Les conteneurs applicatifs ne sont jamais directement accessibles depuis l’extérieur.
Pipeline CI/CD : du push au déploiement
Le pipeline CI/CD de SmartPlanning repose sur GitHub Actions avec trois workflows distincts qui couvrent l’ensemble du cycle de vie du code.
Workflow CI : valider chaque changement
Chaque fonctionnalité suit un workflow Git professionnel avant même d’atteindre la CI : branche feature isolée, commits atomiques en Conventional Commits, Pull Request avec review, puis merge déclenche le déploiement automatique.
 Workflow Git : de la branche feature au déploiement, chaque étape est tracée et automatisée
Workflow Git : de la branche feature au déploiement, chaque étape est tracée et automatisée
A chaque push, le workflow CI se déclenche et exécute quatre étapes en séquence :
- Lint et vérification des types TypeScript : le code doit être propre avant d’aller plus loin
- Tests unitaires Vitest : les ~2 814 tests valident la logique métier, les Server Actions, les services
- Build Next.js en production : on vérifie que l’application compile sans erreur
- Tests E2E Playwright (~189 scénarios) : déclenchés sur les PRs vers
mainet les push directs, ils valident les parcours utilisateurs critiques de bout en bout
Durée totale : 8 à 10 minutes. Assez rapide pour ne pas casser le rythme de développement, assez complet pour attraper les régressions.
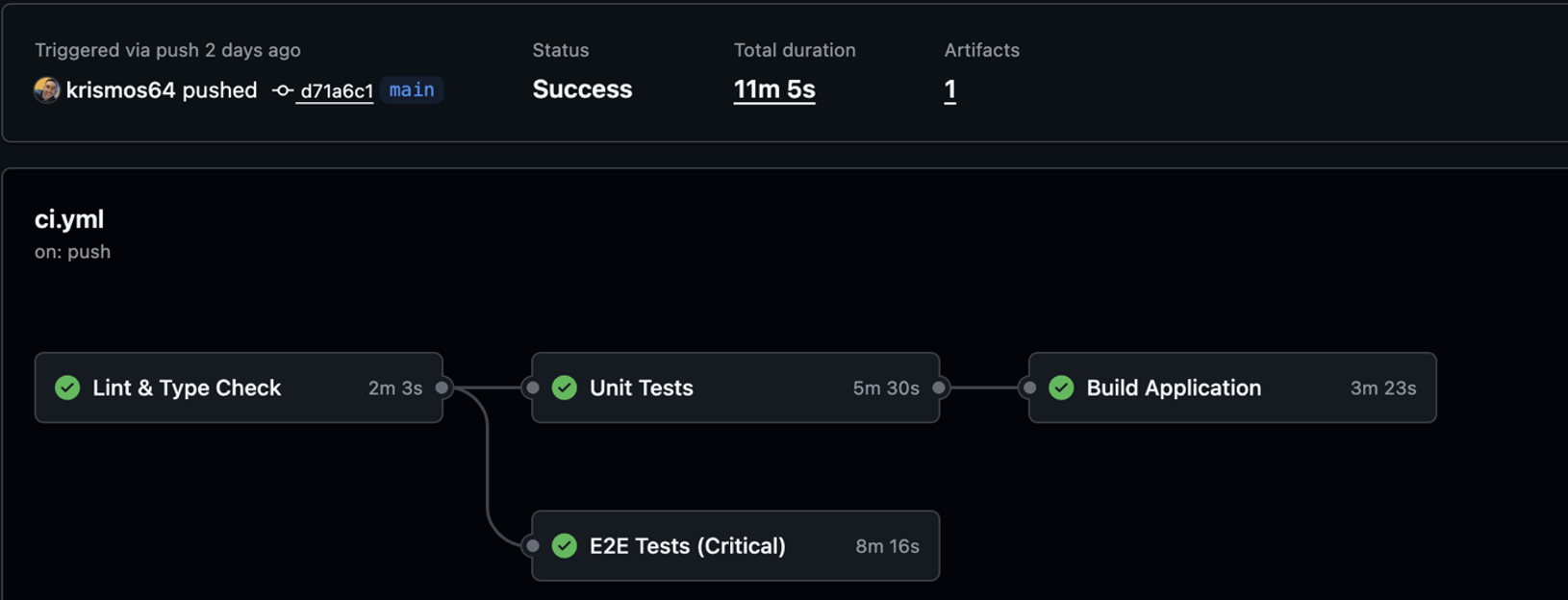 Pipeline CI réel : 4 jobs en 11 minutes, statut Success sur un push vers main
Pipeline CI réel : 4 jobs en 11 minutes, statut Success sur un push vers main
Workflow CD : déployer automatiquement
Quand la CI passe au vert sur main, le déploiement se lance automatiquement :
- Construction de l’image Docker et push vers GitHub Container Registry (GHCR) : le registre d’images est privé et intégré à GitHub
- Connexion SSH au VPS, pull de la nouvelle image, exécution des migrations Prisma, redémarrage des services Docker
Le tout en environ 7 minutes. Du merge de la PR au site live, sans intervention manuelle.
 Pipeline CD : 7 étapes séquentielles du push jusqu’au redémarrage des services en production
Pipeline CD : 7 étapes séquentielles du push jusqu’au redémarrage des services en production
Workflow Nightly : surveiller la stabilité
Chaque nuit, un troisième workflow exécute la suite complète de tests E2E. L’objectif : détecter les régressions silencieuses, celles qui passent inaperçues dans le contexte d’une PR isolée mais qui cassent un parcours utilisateur quand elles interagissent avec d’autres changements.
Gestion des secrets
Les secrets sensibles : clés SSH, tokens API, identifiants de base de données : sont chiffrés dans GitHub Secrets. Ils ne sont jamais exposés dans le code source, ni dans les logs de CI. C’est un principe non négociable : aucune donnée sensible en clair dans le dépôt.
Sécurité serveur : les leçons d’un incident réel
En décembre 2025, SmartPlanning a été impacté par la CVE-2025-66478, une vulnérabilité critique de Next.js notée 10.0/10 sur l’échelle CVSS. Combinée à une configuration serveur insuffisamment durcie, cette faille a nécessité une migration complète vers un nouveau VPS : une base propre, reconstruite de zéro.
Cette expérience a été un tournant. Voici les mesures mises en place :
- SSH durci : authentification par clé Ed25519 uniquement, désactivation complète de l’authentification par mot de passe
- Fail2ban : blocage automatique des IP suspectes après tentatives d’accès répétées
- UFW (pare-feu) : politique de refus par défaut (
deny all), seuls les ports strictement nécessaires sont ouverts (HTTP, HTTPS, SSH) - GitHub Secrets : chiffrement systématique de toutes les variables sensibles
- Conteneurs Docker durcis : les mesures OWASP décrites plus haut
Un incident de sécurité n’est jamais agréable, mais celui-ci m’a forcé à passer d’une sécurité “suffisante” à une sécurité intentionnelle et documentée. Chaque décision est tracée, chaque configuration justifiée.
Monitoring et performance
Un déploiement automatisé ne suffit pas : il faut aussi surveiller ce qui tourne en production.
Health check applicatif
L’endpoint /api/health mesure en temps réel la latence de la base de données. Au-delà de 500 ms, le statut passe en degraded. C’est un indicateur simple mais efficace pour détecter les problèmes avant qu’ils n’impactent les utilisateurs.
Analytics auto-hébergé
Umami remplace Google Analytics avec un avantage décisif : il est auto-hébergé sur le même VPS, ne dépose aucun cookie tiers et est nativement conforme au RGPD. Les données restent sous mon contrôle, sur mon infrastructure.
Performance mesurée
L’audit Lighthouse de la page d’accueil en production affiche un score de 96/100 en performance. Ce résultat est le fruit de plusieurs optimisations combinées : le rendu SSR qui réduit le travail du navigateur, les images optimisées via Cloudinary, la pagination côté serveur qui évite le chargement de données inutiles, et le build standalone de Next.js qui produit une image Docker de taille minimale.
Eco-conception : produire moins, servir mieux
L’infrastructure de SmartPlanning intègre des principes d’éco-conception à chaque niveau :
- SSR systématique : le rendu côté serveur réduit la charge de calcul côté navigateur
- Images optimisées via Cloudinary : compression, redimensionnement, formats modernes
- Pagination serveur : les tableaux de données ne chargent que ce qui est nécessaire, pas l’intégralité d’une collection
- Build standalone : l’image Docker de production ne contient que le strict nécessaire, pas les dépendances de développement
Ce ne sont pas des optimisations cosmétiques. Elles réduisent concrètement la bande passante consommée, la charge CPU serveur et le temps de chargement côté utilisateur.
Ce que cette infrastructure m’a appris
Mettre en place l’ensemble de cette chaîne : de Docker à la CI/CD en passant par le durcissement serveur : m’a appris une chose essentielle : le déploiement n’est pas une étape finale, c’est une discipline continue.
Chaque composant de cette infrastructure a été choisi, configuré et durci avec intention. Le VPS autogéré m’a forcé à comprendre ce que les PaaS cachent. L’incident de sécurité m’a appris que “ça marche” ne suffit pas : il faut que ce soit robuste par design. Et le pipeline CI/CD, avec ses 3 000+ tests exécutés à chaque changement, me donne la confiance nécessaire pour déployer plusieurs fois par semaine sans appréhension.
Pour un développeur fullstack, maîtriser la chaîne complète du code à la production n’est pas un bonus : c’est ce qui distingue un développeur qui livre des fonctionnalités d’un développeur qui livre un produit fiable.
Dans le prochain article, je présenterai des démonstrations concrètes des fonctionnalités de SmartPlanning en action.